Let's Shape The Future Of Your Investments!
Natoque iaculis cursus augue urna commodo aptent morbi tortor porttitor quis ornare.



在本教程中,我将详细介绍如何在本地环境下,使用 Ollama 和 Chatbox 部署 DeepSeek-R1 模型。通过这些步骤,您可以在个人电脑上运行该模型,实现高效的 AI 交互体验。
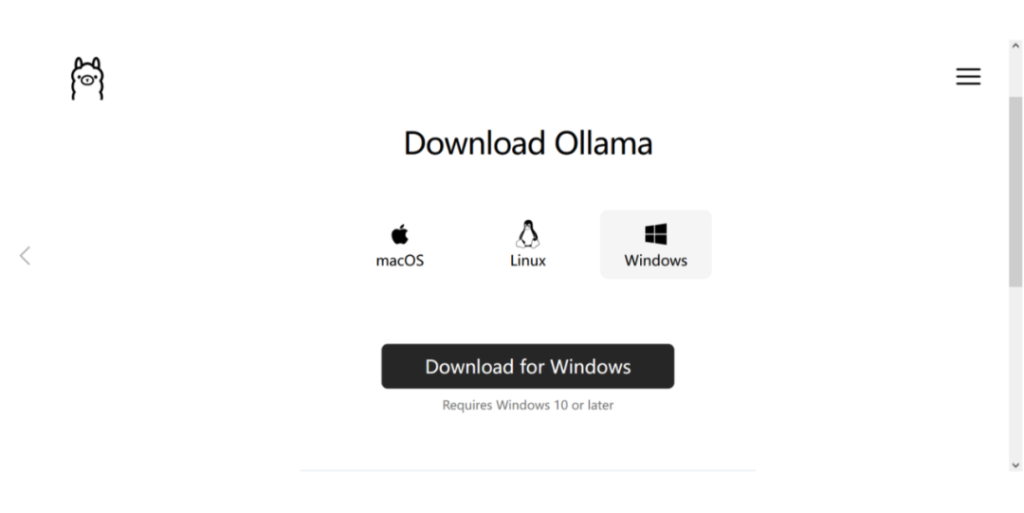
下载 Ollama:访问 Ollama 官方网站,根据您的操作系统选择相应的安装包进行下载。
安装 Ollama:运行下载的安装包,按照提示完成安装过程。安装完成后,您可以在系统托盘中看到 Ollama 的图标,表示其正在运行。
安装验证:安装完成后,为了确认 Ollama 是否成功安装,MacOS系统在终端输入 ollama -v 。如果安装正确,终端会显示 Ollama 的版本号,这就表明你已经成功完成了基础环境搭建的第一步。(windows 的话,win+r 输入 cmd)
ollama -v一)依据硬件精准选型
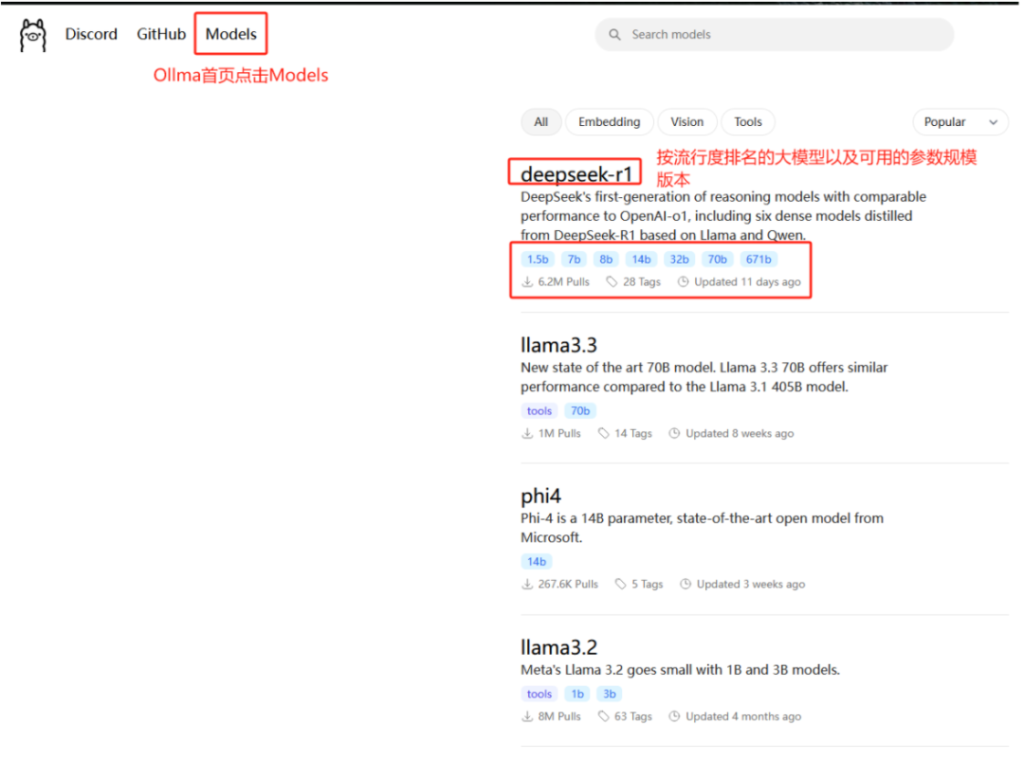
打开Ollama 模型库,你会看到丰富多样的 DeepSeek-R1 模型版本,如 1.5B、7B、32B 等。根据自身电脑硬件配置来选择合适的模型版本至关重要。
通用配置原则
- 模型显存占用(估算):
- 每 1B 参数约需 1.5-2GB 显存(FP16 精度)或 0.75-1GB 显存(INT8/4-bit 量化)。
- 例如:32B 模型在 FP16 下需约 48-64GB 显存,量化后可能降至 24-32GB。
- 内存需求:至少为模型大小的 2 倍(用于加载和计算缓冲)。
- 存储:建议 NVMe SSD,模型文件大小从 1.5B(约 3GB)到 32B(约 64GB)不等。
以下按模型规模和平台分类,提供 最低配置 和 推荐配置。
| 平台 | 最低配置 | 推荐配置 |
|---|---|---|
| Windows | – CPU: Intel i5 / Ryzen 5 | – CPU: Intel i7 / Ryzen 7 |
| – RAM: 8GB | – RAM: 16GB | |
| – GPU: NVIDIA GTX 1650 (4GB) | – GPU: RTX 3060 (12GB) | |
| macOS | – M1/M2 芯片(8GB 统一内存) | – M1 Pro/Max 或 M3 芯片(16GB+) |
| Linux | – CPU: 4 核 | – CPU: 8 核 |
| – RAM: 8GB | – RAM: 16GB | |
| – GPU: NVIDIA T4 (16GB) | – GPU: RTX 3090 (24GB) |
| 平台 | 最低配置 | 推荐配置 |
|---|---|---|
| Windows | – CPU: Intel i7 / Ryzen 7 | – CPU: Intel i9 / Ryzen 9 |
| – RAM: 16GB | – RAM: 32GB | |
| – GPU: RTX 3060 (12GB) | – GPU: RTX 4090 (24GB) | |
| macOS | – M2 Pro/Max(32GB 统一内存) | – M3 Max(64GB+ 统一内存) |
| Linux | – CPU: 8 核 | – CPU: 12 核 |
| – RAM: 32GB | – RAM: 64GB | |
| – GPU: RTX 3090 (24GB) | – 多卡(如 2x RTX 4090) |
| 平台 | 最低配置 | 推荐配置 |
|---|---|---|
| Windows | – GPU: RTX 3090 (24GB) | – GPU: RTX 4090 + 量化优化 |
| – RAM: 32GB | – RAM: 64GB | |
| macOS | – M3 Max(64GB+ 统一内存) | – 仅限量化版本,性能受限 |
| Linux | – GPU: 2x RTX 3090(通过 NVLink) | – 多卡(如 2x RTX 4090 48GB) |
| – RAM: 64GB | – RAM: 128GB |
| 平台 | 最低配置 | 推荐配置 |
|---|---|---|
| Windows | – 不推荐(显存不足) | – 需企业级 GPU(如 RTX 6000 Ada) |
| macOS | – 无法本地部署(硬件限制) | – 云 API 调用 |
| Linux | – GPU: 4x RTX 4090(48GB 显存) | – 专业卡(如 NVIDIA A100 80GB) |
| – RAM: 128GB | – RAM: 256GB + PCIe 4.0 SSD |
建议根据实际硬件选择蒸馏版本,并优先在 Linux 环境下部署大模型。
这里示例参考 DeepSeek-R1-7b 模型:
接下来在命令行中输入以下命令,下载并运行 DeepSeek-R1-7b 模型:
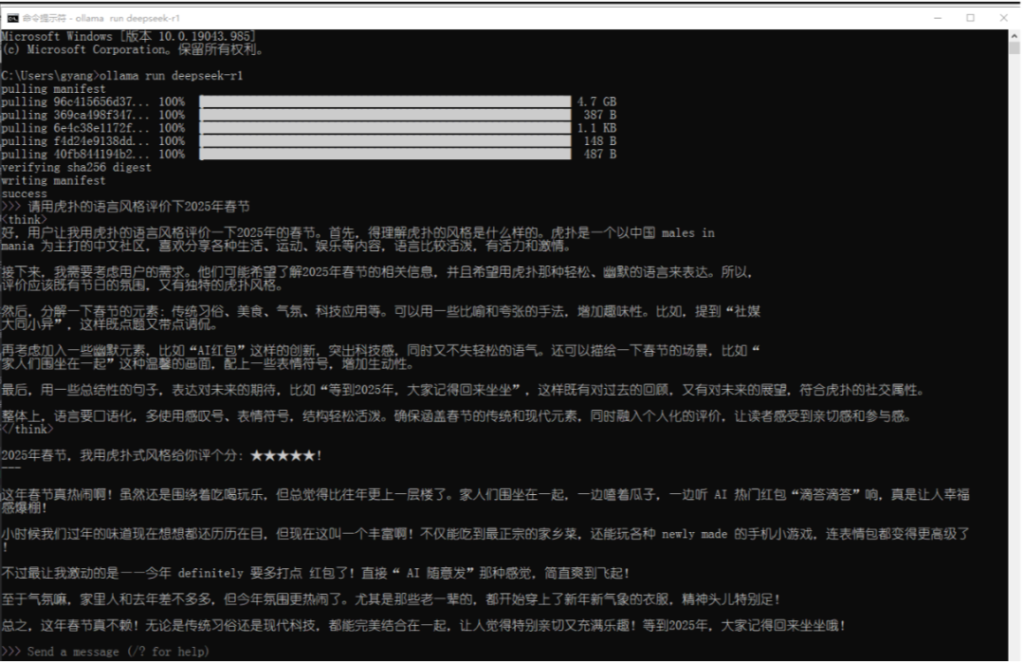
ollama run deepseek-r1:7b如果是第一次运行,Ollama 会自动下载模型文件,请耐心等待。
模型运行后,可以直接在命令行中与 DeepSeek 交互。尝试您测试的命令,DeepSeek 会生成对应的回答。
为了提升与DeepSeek模型的交互体验,我们可以安装ChatBox,并通过其图形用户界面(GUI)调用Ollama的API。
ChatBox是一款AI客户端应用和智能助手,支持众多先进的AI模型和API调用,同样可在Windows、MacOS、Linux等桌面系统上使用,难能可贵地是,ChatBox还提供IOS与Android等移动端和网页端使用。
下载步骤:
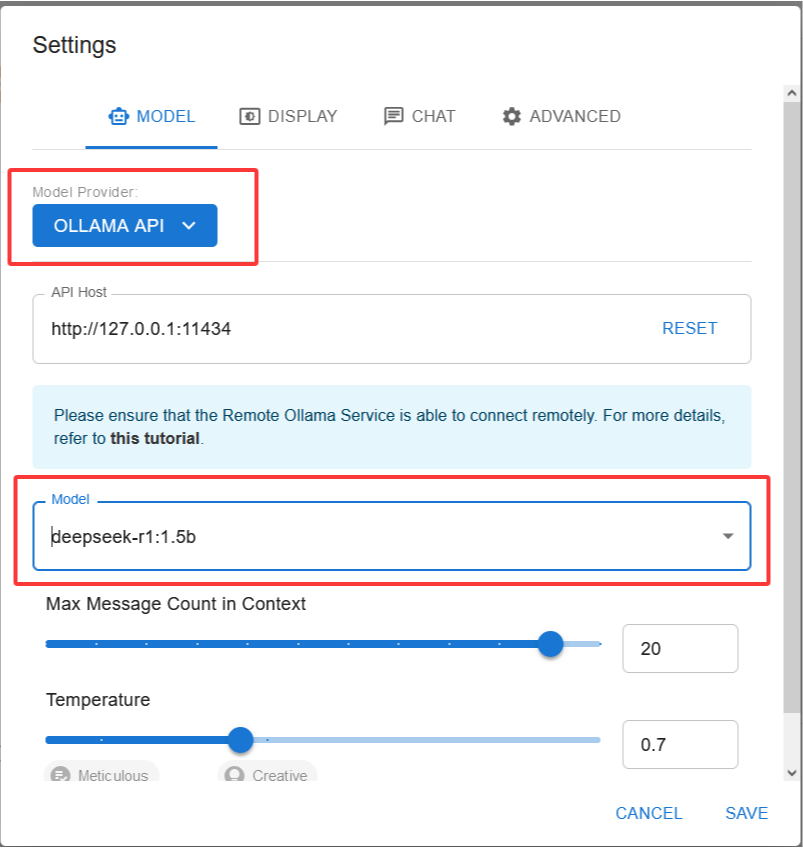
安装完成后,打开ChatBox,在Setting中选择Ollama-API,并在相应的模型中选择DeepSeek。如果没有可用的模型,需要根据自己的操作系统进行相应的本地配置。配置完成后保存即可在新对话中与DeepSeek进行对话啦!
「MacOS配置」
1.打开命令行终端,输入以下命令:
launchctl setenv OLLAMA_HOST "0.0.0.0"
launchctl setenv OLLAMA_ORIGINS "*" 2.重启Ollama应用,使配置生效。
「Windows配置」
在Windows上,Ollama会继承用户和系统环境变量。
通过以上步骤,您即可在本地成功部署 DeepSeek-R1 模型,并通过 Chatbox 实现便捷的交互体验。